简介
- 最近入手了块Chipwhisperer-lite,决定先跟着官方教程学习了解侧信道攻击
- New-AE官网:https://www.newae.com/
- Chipwhisperer官方GitHub仓库:https://github.com/newaetech/chipwhisperer
- Chipwhisperer软件环境官方安装教程:https://chipwhisperer.readthedocs.io/en/latest/index.html
指令能耗差异
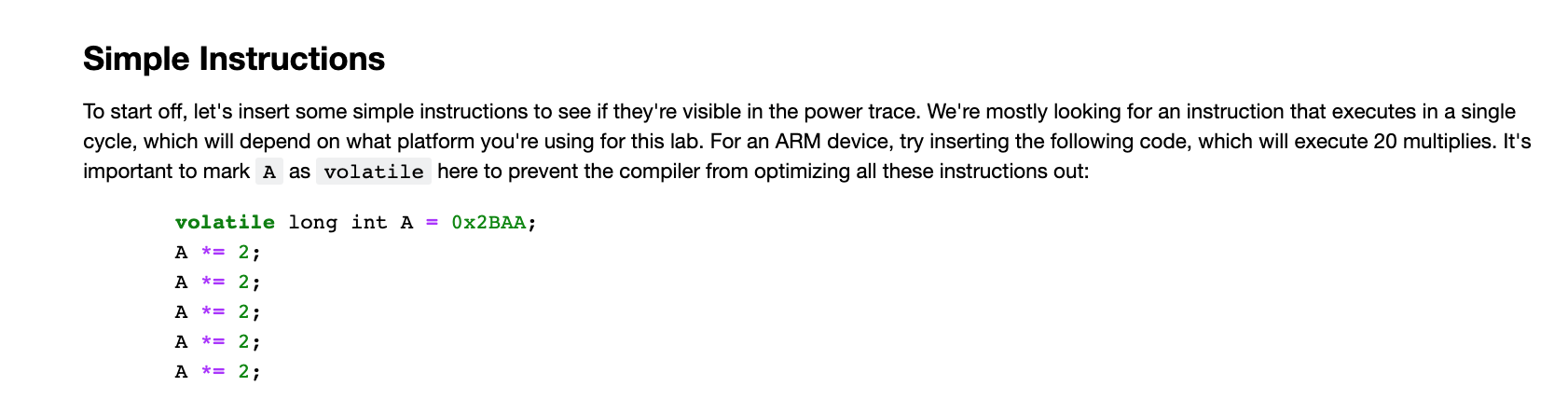
本篇将跟着官方的chipwhisperer-jupyter教程sca101的**Lab 2_1A - Instruction Power Differences **学习CPU运行不同指令时消耗的能量差异
首先可以看到sca101目录下有三个Lab 2_1A - Instruction Power Differences 的.ipynb文件,其实从后缀就可以看出,第二个是主程序的代码,第一个对应的是拥有Chipwhisperer硬件时可运行的代码,第三个是没有硬件时模拟运行的代码

打开MAIN的ipynb,可以看到,最前面有提示选择模拟的代码块或者硬件的代码块复制到这个notebook代码中

打开HARDWARE的ipynb,可以看到最前面有以下提示,意思是:需要根据你的硬件设备先设置相应平台类型,CWLite和CW1200的SCOPETYPE选择'OPENADC',CWNANO则选择'CWNANO';如果目标板为STM32(如:CWLITEARM的目标板就是这个)PLATFORM选择'CWLITE',如果目标板为XMEGA(如:CWLITEXMEGA的目标板就是这个)则选择'CWLITEXMEGA'

这里我的硬件是CWLITEXMEGA所以选择
1
2SCOPETYPE = 'OPENADC'
PLATFORM = 'CWLITEXMEGA'设置好后,把所有HARDWARE的ipynb的代码复制到MAIN的ipynb中执行
编译目标板固件,上面的设置就是为了编译输出合适的目标板固件
用USB连接设备,继续往下运行,正常运行会输出Found ChipWhisperer
给目标板烧录新编译的固件

再往下就是MAIN ipynb的代码了
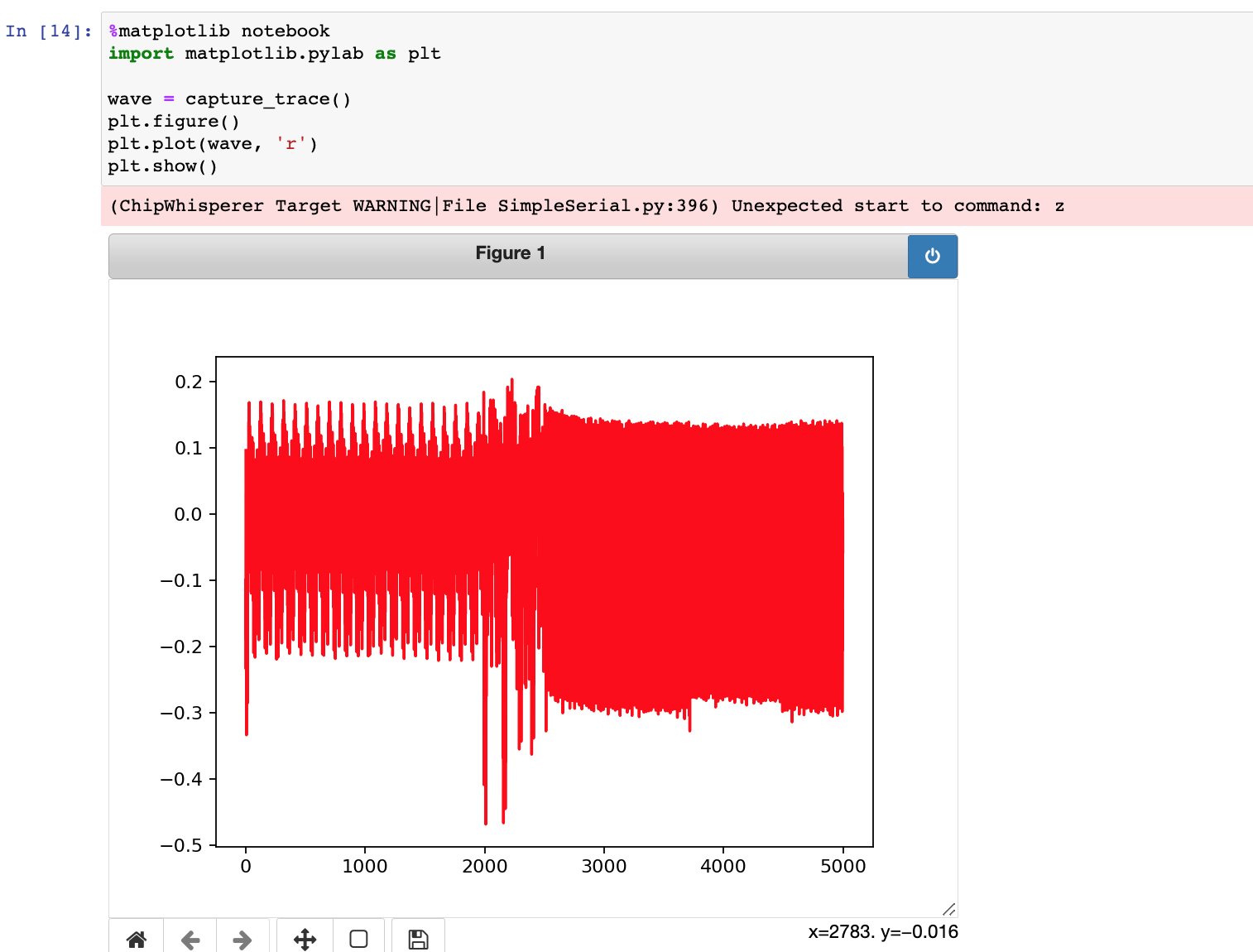
接着可以看到如下提示,意思是,这里只需要关注单个指令的能量消耗,而不关注串口通信的能量消耗,所以需要去'hardware/victims/firmware/simpleserial-base-lab2'目录下修改simpleserial-base.c的代码,找到get_pt函数,删除或者注释调末尾的simpleserial_put调用语句,保存后重新编译并上传至目标板


编译,只需重新执行前面make命令的代码块,即可
1
2
3%%bash -s "$PLATFORM"
cd ../../../hardware/victims/firmware/simpleserial-base-lab2
make PLATFORM=$1 CRYPTO_TARGET=NONE然后再执行前面的给目标板烧录固件的代码即可
1
cw.program_target(scope, prog, "../../../hardware/victims/firmware/simpleserial-base-lab2/simpleserial-base-{}.hex".format(PLATFORM))
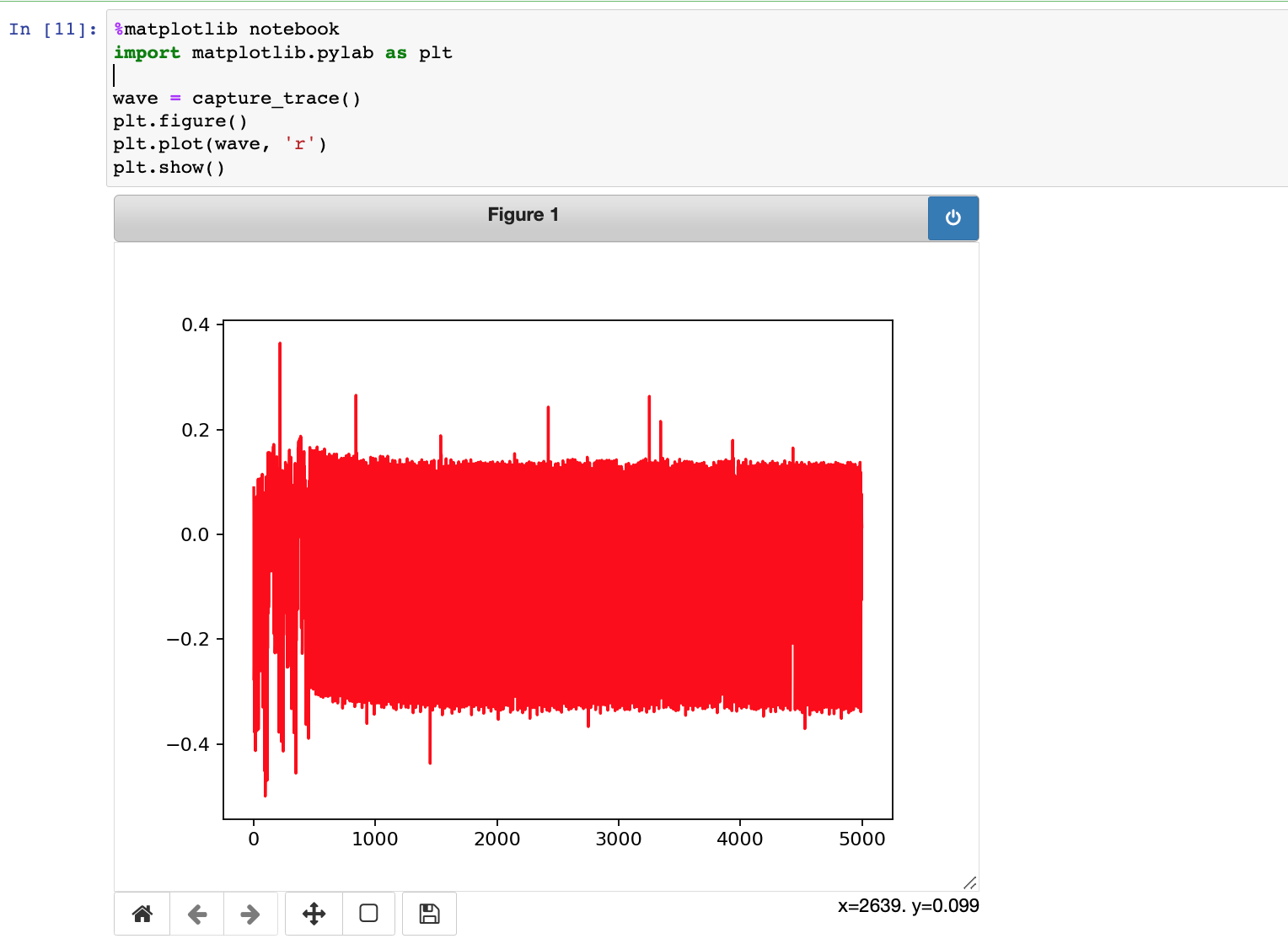
接着往下执行,可以查看目标板的能量消耗曲线
接着往下可以看到如下提示,大意是修改simpleserial-base.c中的代码,让CPU重复执行单一命令20次,看能否从能量消耗曲线中看出该命令所对应的位置,其中需要用"volatile"关键字修饰变量,避免编译器对该代码进行优化(将这些指令直接替换为这些运算的最终结果)。对于不同的目标板,建议选则的指令不一样,如:ARM(STM32)的目标板建议测试乘法运算,XMEGA和AVR则建议测试加法运算(因为这类设备乘法运算消耗更大)
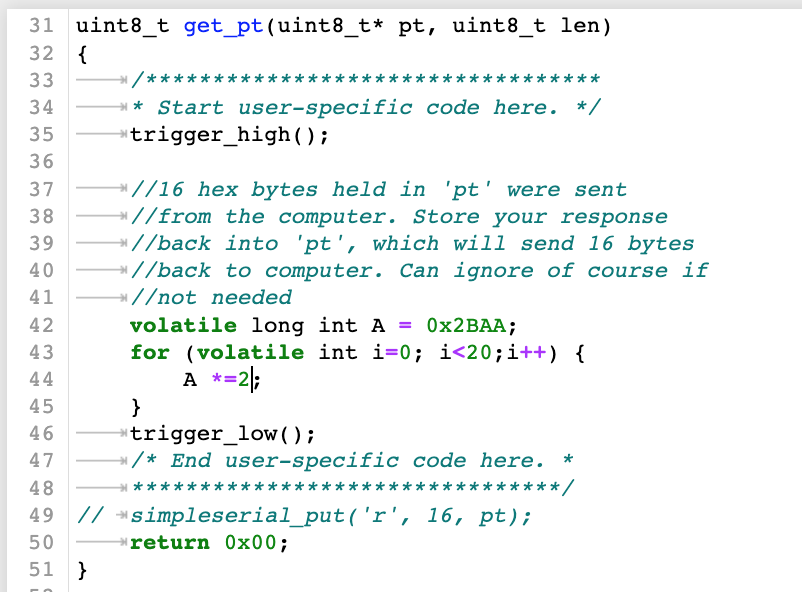
按照上面提示在simpleserial-base.c的get_pt函数中添加测试的加法代码

重新编译并烧录进目标板后,再次画能量消耗图,可以看到如下结果
对比上图和一开始的图片,可以看到,上面前面部分明显出现20个尖峰,结合代码可知,这20个尖峰其实就是目标板运算20次A+=2所对应的能量消耗
再往下可以看到如下提示,大意是,“你可能觉得很奇怪,为什么我们不用一个循环而是复制粘贴一行代码20次。将这个替换为循环你就知道为什么了,需要注意的是循环的变量同样要用volatile修饰”

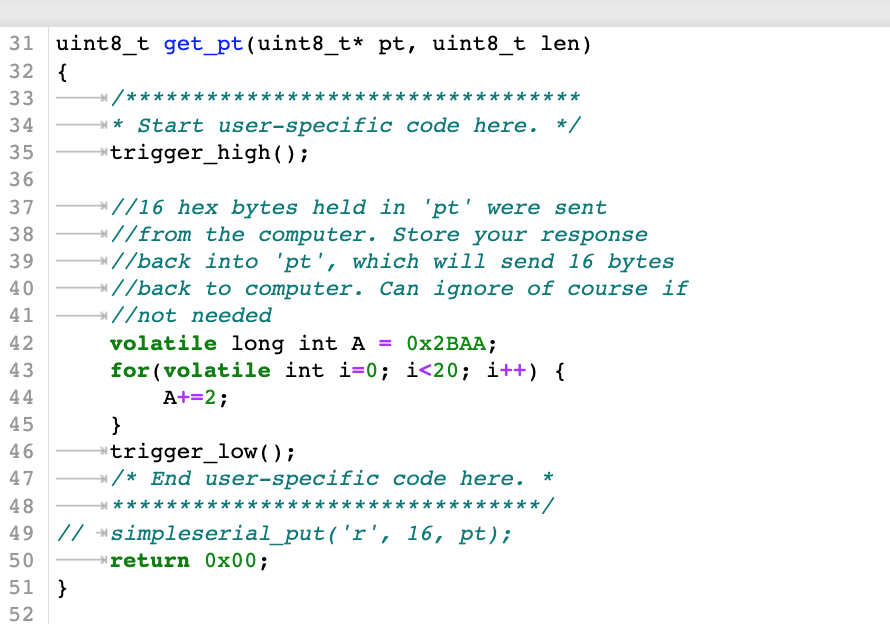
按照上述提示,将该代码改写为for 循环并用volatile修饰循环计数 i,保存并重新编译上传至目标板
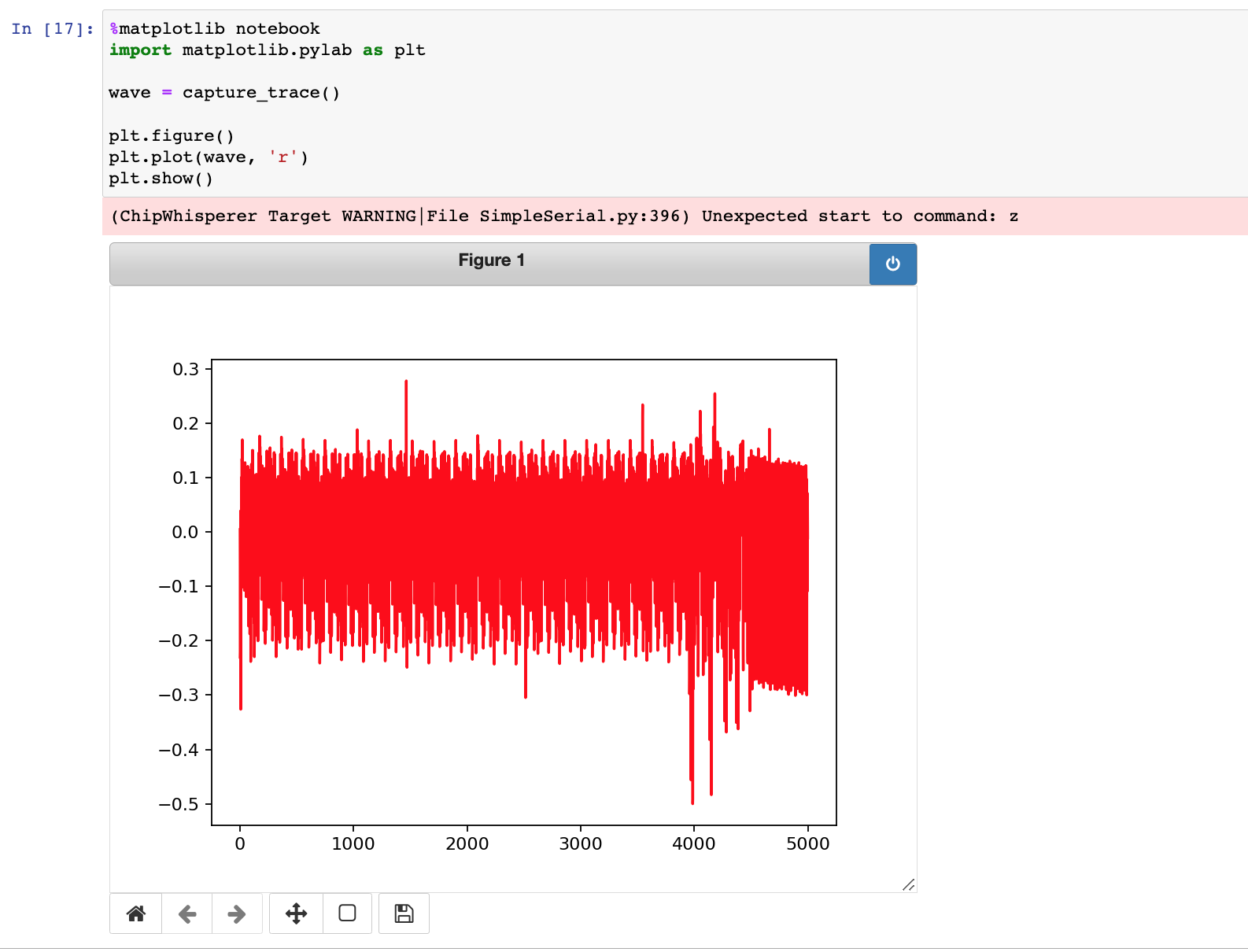
再次画出能量消耗图,如下图,可以看到,虽然同样出现20个周期性的峰型,但是对比复制粘贴执行的能量消耗,下图耗时更久,波形更复杂些
往下可以看到提示,大意是“你可能觉得很奇怪,为什么循环执行更复制粘贴执行的能量消耗结果不一样?如果你熟悉汇编,你可以去查看simpleserial-base-lab2文件夹下的.lss(编译输出的中间文件)。或者看下面这个C伪代码。正如你所看到的,微控制器比起执行重复粘贴的代码,循环需要做更多的事情(比较大小,循环体,循环计数+1)。如果i的变量不用volatile修饰,那么通常会将循环展开(即将循环优化为复制粘贴的代码),有volatile可以避免编译器进行这项优化。当然展开循环会导致代码块大小增大,所以有时编译器为了优化代码块大小而避免展开循环”

再往下可以看到如下提示信息,大意是让我们测试高消耗的运算,对于ARM建议测试除法运算,对于AVR/XMEGA则建议测试乘法运算

但是按照提示将+=2改为*=2后,重新编译并上传目标板后,抓取的能量消耗图与前面相比却并没有太大区别
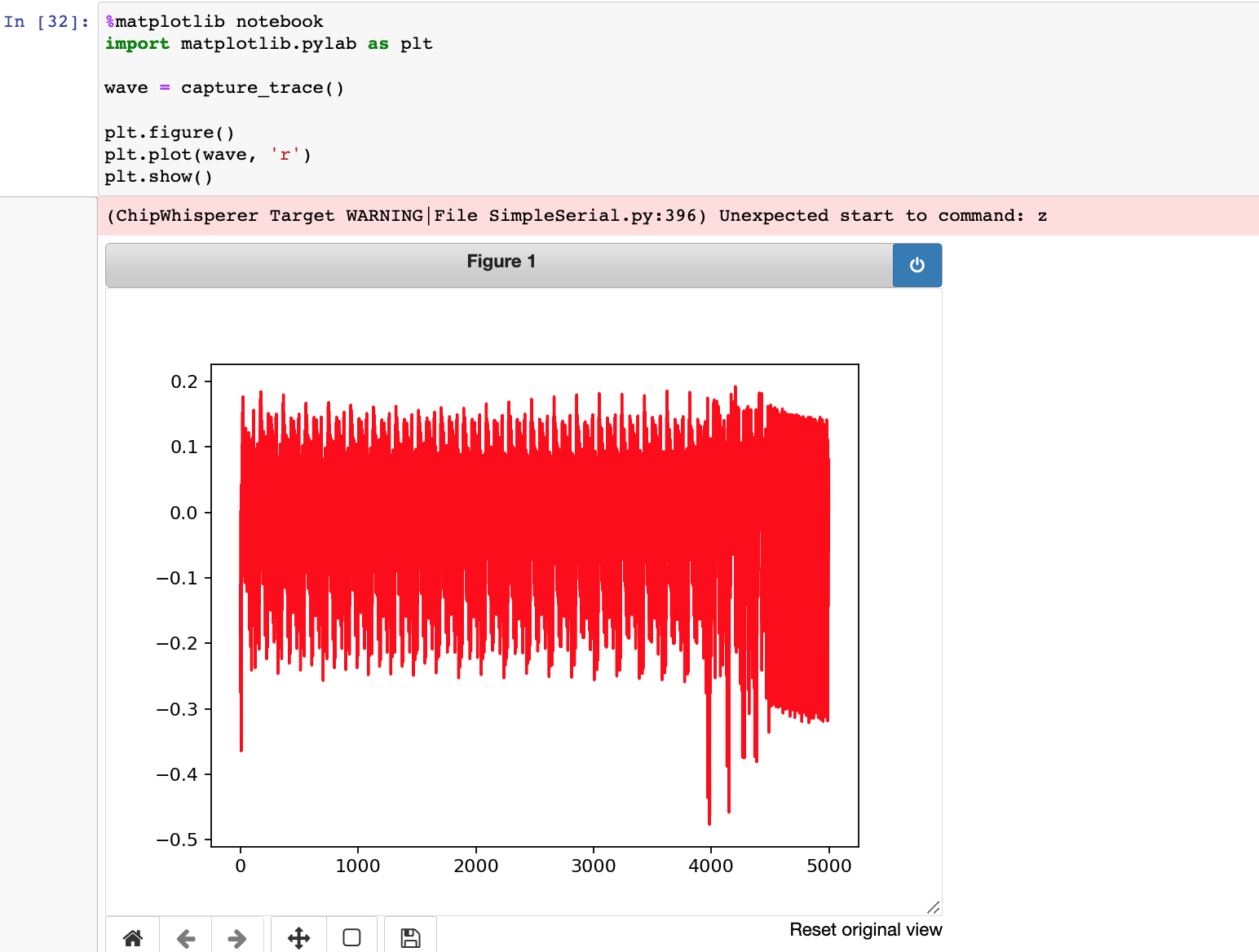
按下面的提示,可以知道,改为复杂运算后,应该会花更多的时间运算而且消耗更多的能量,但是上面*=2的与前面+=2却并没有太大区别

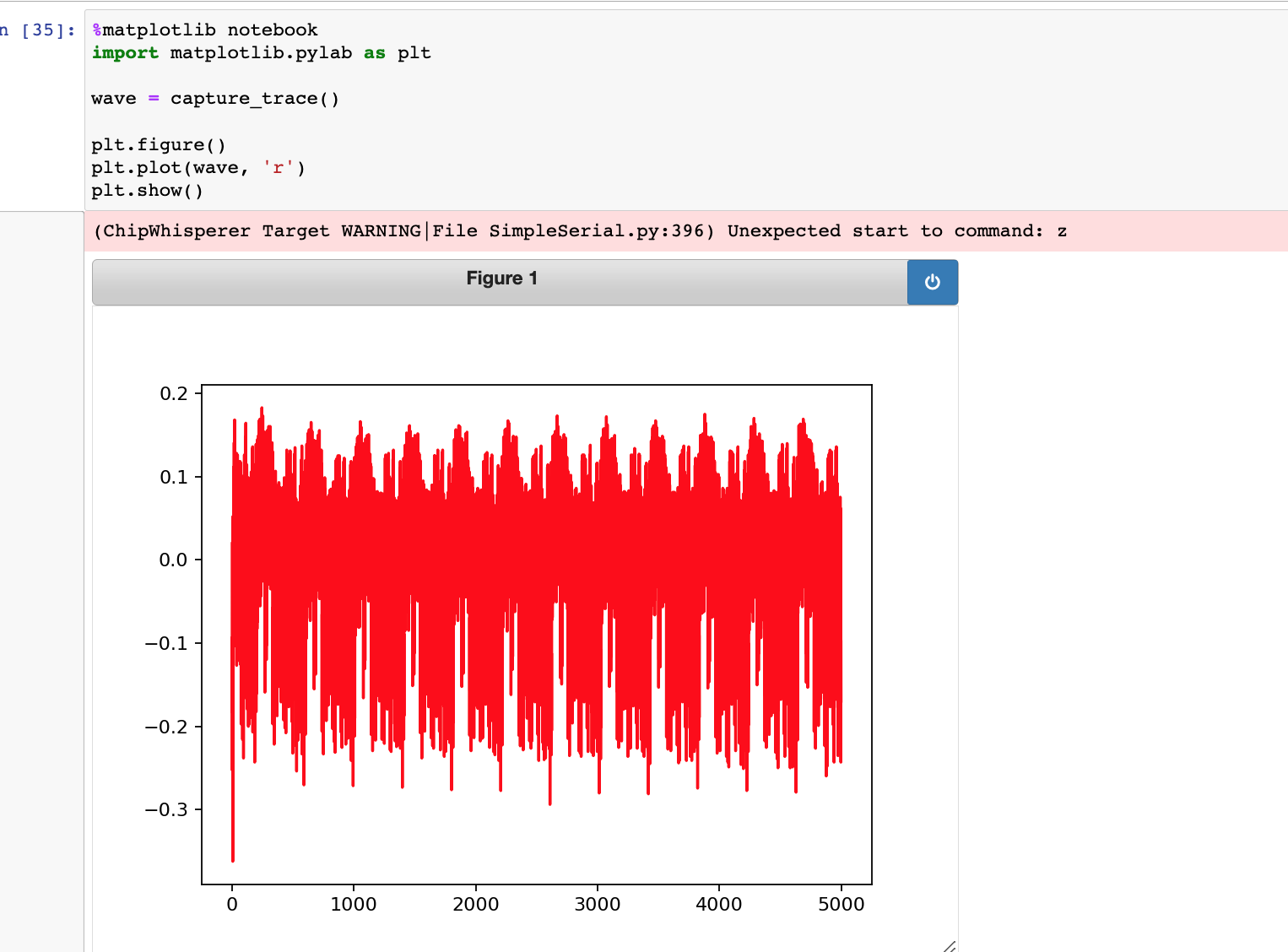
不过想到编译器可能对2的倍数的乘法运算有优化,将乘法优化为移位运算了(如*2优化为<<1),于是把2改为3,重新编译测试,结果一出来,果然乘法消耗明显更大
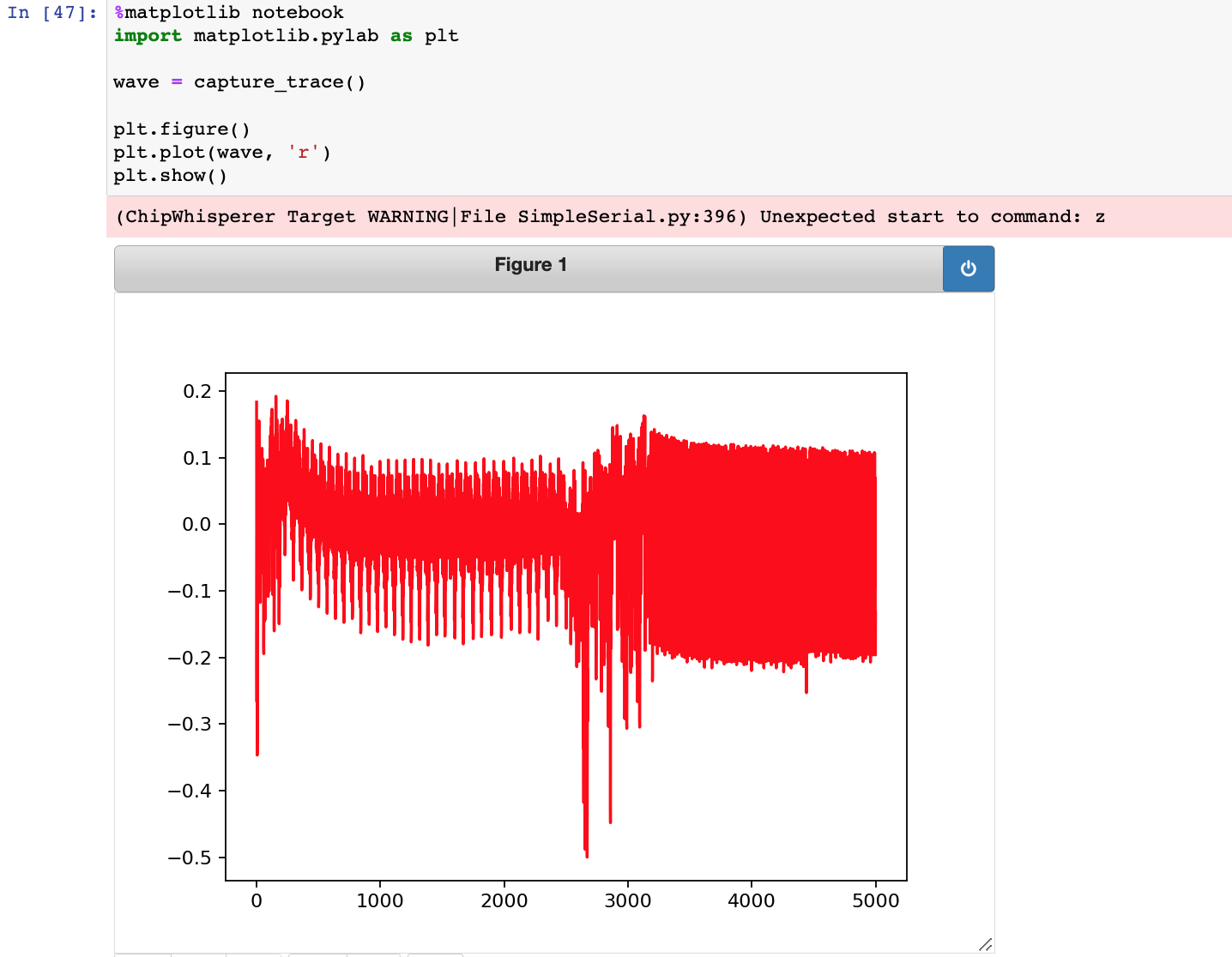
再来试试除法,根据提示的意思是XMEGA中的除法开销会巨大,如下图,下图这其实只是1次除法运算的能量消耗图而不是20次,如此可见XMEGA中的除法消耗的确非常大。同样从单次除法运算中出现多个尖峰可以推测,可以推测XMEGA的除法是循环运算一些简单指令得到的
总结
- CPU/微控制器执行不同指令会有不同能量消耗和时间消耗
- 编译器可能会在编译时对一些代码做一些优化,如:把简单的运算之间替换为运算结果,循环展开等,所以有时候测试某些运算/指令的能量消耗时,需要特别留意最终的可执行程序是否被编译器优化过的