简介
- 本篇将继续跟随chipwhisperer-jupyter sca101的教程来学习了解能量分析中的常用模型 汉明重量
- 汉明重量:简单来说就是一个数的二进制包含'1'的个数,如0x00的HM为0,0xFF的HM为8,0x1和0x2的HM都为1
开始
如下图,同样选择复制HARDWARE的代码至MAIN中

同样地根据提示信息选择平台,这里需要注意的是:XMEGA平台的CRYPTO_TARGET既可以使用默认值'TINYAES128C'(全平台通用)也可以使用'AVRCRYPTOLIB'(仅限XMEGA)

前几行代码,依旧是初始化一些参数和编译并上传合适的固件到目标板中
接着就是提示信息和相应的代码,大意是说为了查看不同汉明重量的数据对能量消耗的影响,这里生成两种极端数据'0x00'(00000000)和'0xff'(11111111),100个traces就足够查看两者的差异

接着往下运行,可以看到如下提示信息,大意是指:查看HM大的0xFF和HM小的0x00数据对运行AES时的能量消耗差异,由于这些数据是混合在一起的,所以首先需要对抓取的数据进行分组,分为one_list和zero_list

按照提示修改代码将数据分为两组,并将结果转为numpy array类型
1
2
3
4
5
6
7
8
9zero_list=[]
one_list=[]
for i in range(len(trace_array)):
if textin_array[i][0] == 0x00:
zero_list.append(trace_array[i])
else:
one_list.append(trace_array[i])
1
2
3
4
5
6
one_list=np.array(one_list)
zero_list=np.array(zero_list)
assert len(one_list) > len(zero_list)/2
assert len(zero_list) > len(one_list)/2接着可以看到如下提示信息,大意是:使用np.mean分别对上面两组数据的trace求平均值,得到zero_avg和one_avg的数据,其中'axis'参数可用来指定求均值的方向(按行或者按列求)

按照提示信息,修改代码,求两组数据的平均值,
1
2
3
4
5
6
7trace_length = len(one_list[0])
print("Traces had original sample length of %d"%trace_length)
one_avg=np.mean(one_list, axis=0)
if len(one_avg) != trace_length:
raise ValueError("Average length is only %d - check you did correct dimensions!"%one_avg)1
2
3
4
5
6
7trace_length = len(zero_list[0])
print("Traces had original sample length of %d"%trace_length)
zero_avg=np.mean(zero_list, axis=0)
if len(zero_avg) != trace_length:
raise ValueError("Average length is only %d - check you did correct dimensions!"%zero_avg)最后就是画出两组的差异图
1
2
3
4
5
6
7%matplotlib notebook
import matplotlib.pyplot as plt
diff = one_avg[:1000] - zero_avg[:1000]
plt.plot(abs(diff))
plt.show()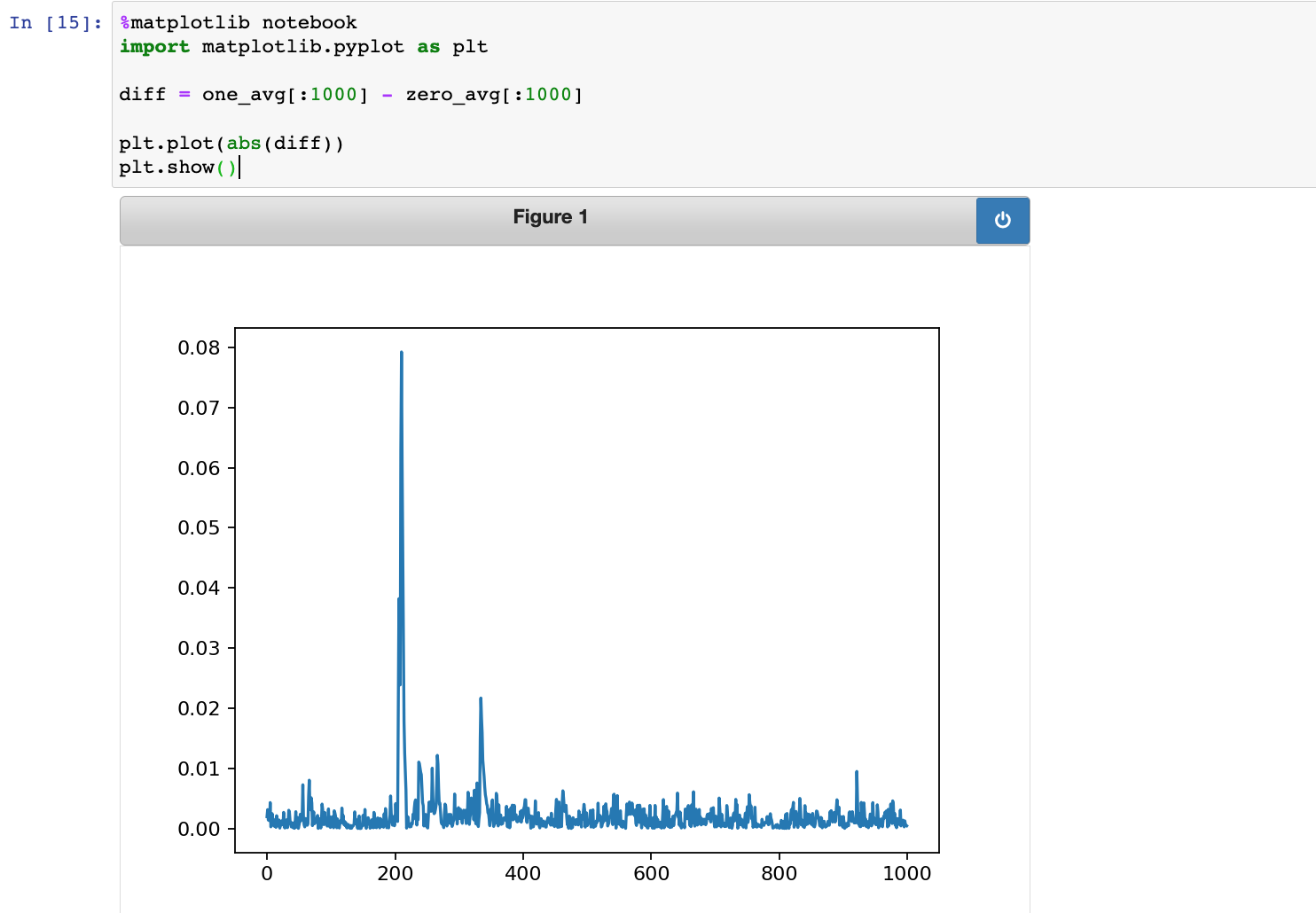
往下可以看到如下提示信息,大意是说:在前面的位置你可以看到一个明显的差异,这个代表着数据的差异也可以在能量图中体现出来。对比上图确实如此,在200的位置可以看到一个明显的峰值,其余部分的差异都非常小

接下来尝试不同的数据与'0x00'的对比,下图'0x01'与'0x00'的对比,可以看到,两者差异并不明显,不能识别出差异数据所在位置
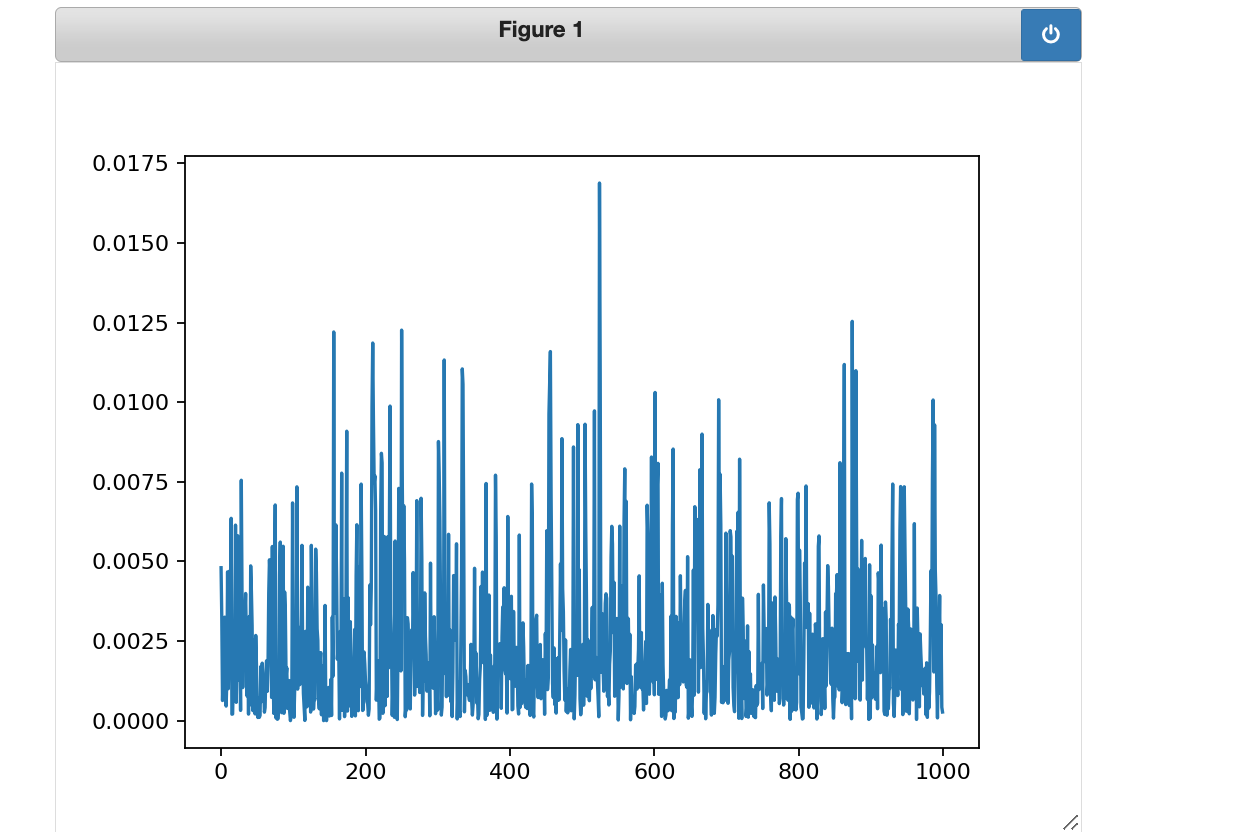
出现上图原因是,抓取的数据太少,将前面的N=100改为N=1000,重新运行,并画图,可以看到同样可以看到一个明显的

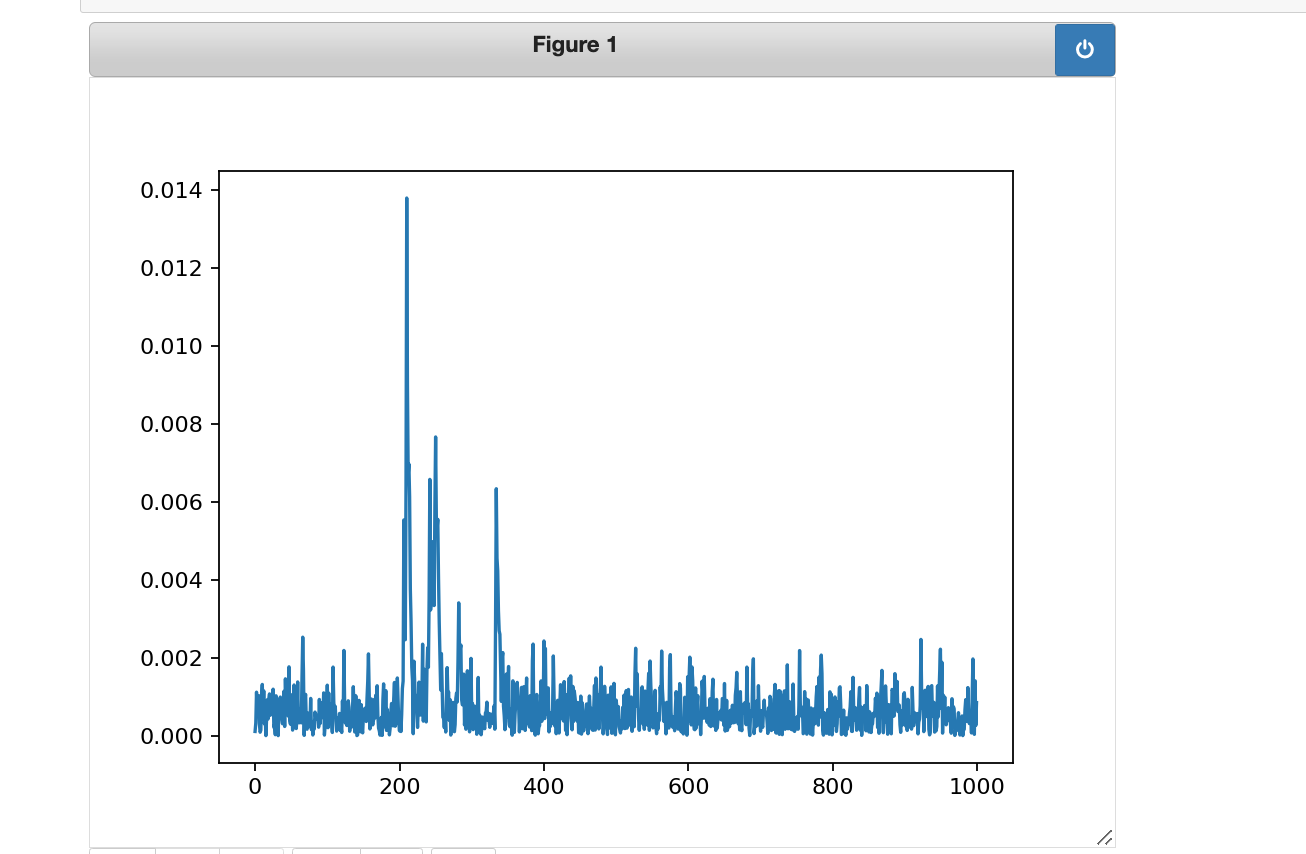
总结
- 除了代码会对能量消耗产生影响外,代码所处理的数据同样会对能量消耗产生影响
- 有时为了区分出数据的细微差异,往往需要抓取更多的数据才能保证出现预期的结果