前言
- 我之前的文章解决selenium使用location定位与截图中的坐标偏差问题中提到了,如何利用selenium截取验证码,但是并没有讲该怎么去识别验证码,原因是之前一直没有找到好的方法,一开始尝试过pillow + pytesseract,但是效果很差,显然这种验证码不能用这方法。也尝试过网上的一些在线识别,效果不错,但缺点就是要钱。
- 再后来在github上发现了这个项目https://github.com/nickliqian/cnn_captcha,然后又在这篇文章中Tensorflow实战(二):Discuz验证码识别找到了生成Discuz验证码的php代码,这篇文章也给出了他的深度学习的识别验证码的代码,但我测试时没跑成功,又不懂这方面的知识,排不了错,所以最后选择的是用cnn_captcha这个项目来训练模型,用他给的php代码生成训练用的数据集。最终发现训练的模型效果还不错,一开始用2万张图片训练,虽然训练集准确率达到了100%,但测试集图片准确率一直为0,增加图片数量得到改善,最后调整到用20万张图片训练,测试集字符识别率和图片准确率均达到了99%,实际测试从目标网站爬取下来的图片识别准确率也有80%,这个准确率自用完全OK。
准备阶段
最好拥有一台有高性能GPU的电脑,不然训练只靠CPU真跑不动,或者可以使用像谷歌的colab这种云平台来训练模型,训练好后再下载下来使用
tensorflow 1.x 环境,试过tensorflow 2.x以兼容1.x方式运行,但是运行还是出了问题,可以用anaconda创建一个tensorflow 1的虚环境,tensorflow1.5下载地址:https://pypi.org/project/tensorflow/1.15.0/#files
php运行环境(生成验证码数据集需要)
如果不想生成验证码或者重复训练模型,这里提供训练用的20万张验证码数据集,以及训练好的模型,模型下载后可以直接使用
链接: https://pan.baidu.com/s/1neXmwUjlqGzxBk3QoqRWCg?pwd=2zx4 密码: 2zx4
注意事项:使用这个模型进行识别需要图片满足width 160,hight 60的png格式,而且要有alpha通道,因为用于训练的图片就是这种。如果你的图片宽高不符合请等比缩放调整至一直,否则会运行出错;如果png图没有alpha通道,请转换下即可,否则将导致识别结果不准确(之前试了同一网站两种不同方式获取验证码图片,识别结果天壤之别,排了很久才发现是识别差的那组是因为图片没有alpha通道,才导致识别结果不准。。)
这个模型比较适合这种类型的Discuz验证码,动态和静态一样,因为最终用于识别的都只有那一张图

开始
生成验证码数据集
首先生成训练用的数据集,一开始是想的从目标网站爬取验证码,爬下来1000张,自己人工标了几百张,大脑就罢工了。。后来找到这个php代码discuz.tar.gz,可以批量生成验证码,还不用自己标注,省去很大麻烦,所以要识别某类验证码,最好看看网上能不能找到相应的验证码库批量生成,实在不行再来考虑爬取标注。
下面讲解如何在不会php的情况下,简单跑起这个生成验证码项目,以MacOS+PHPStorm为例
首先安装php,打开终端用homebrew安装即可:
brew install php下载安装PHPStorm,启动后打开discuz.tar.gz解压后的目录
选择Preferences > PHP > CLI Interpreter > PHP executable,选择php安装目录,一般homebrew安装的在/usr/local/Cellar目录下可以找到,最后选择OK保存即可
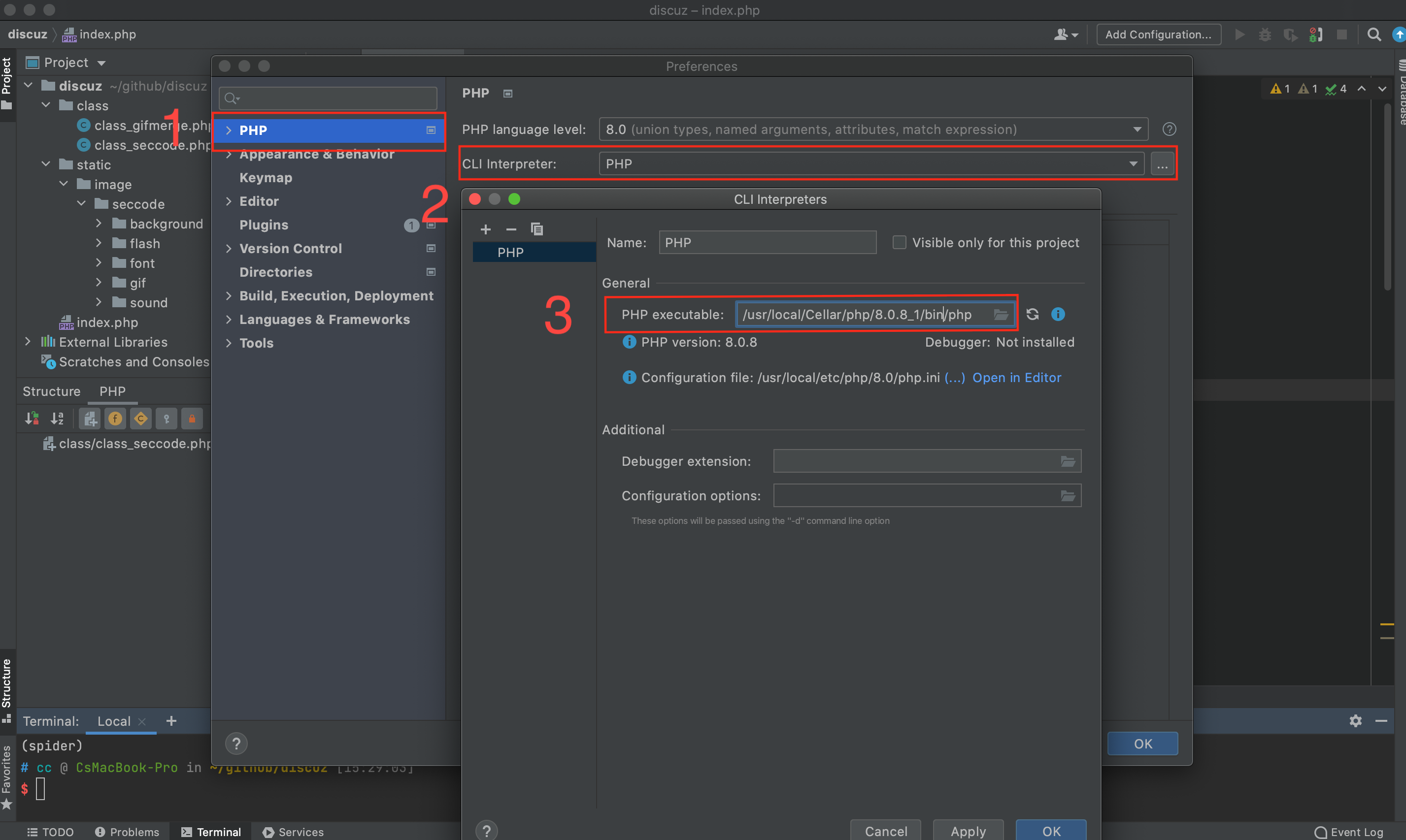
选择右上角Add Configuration
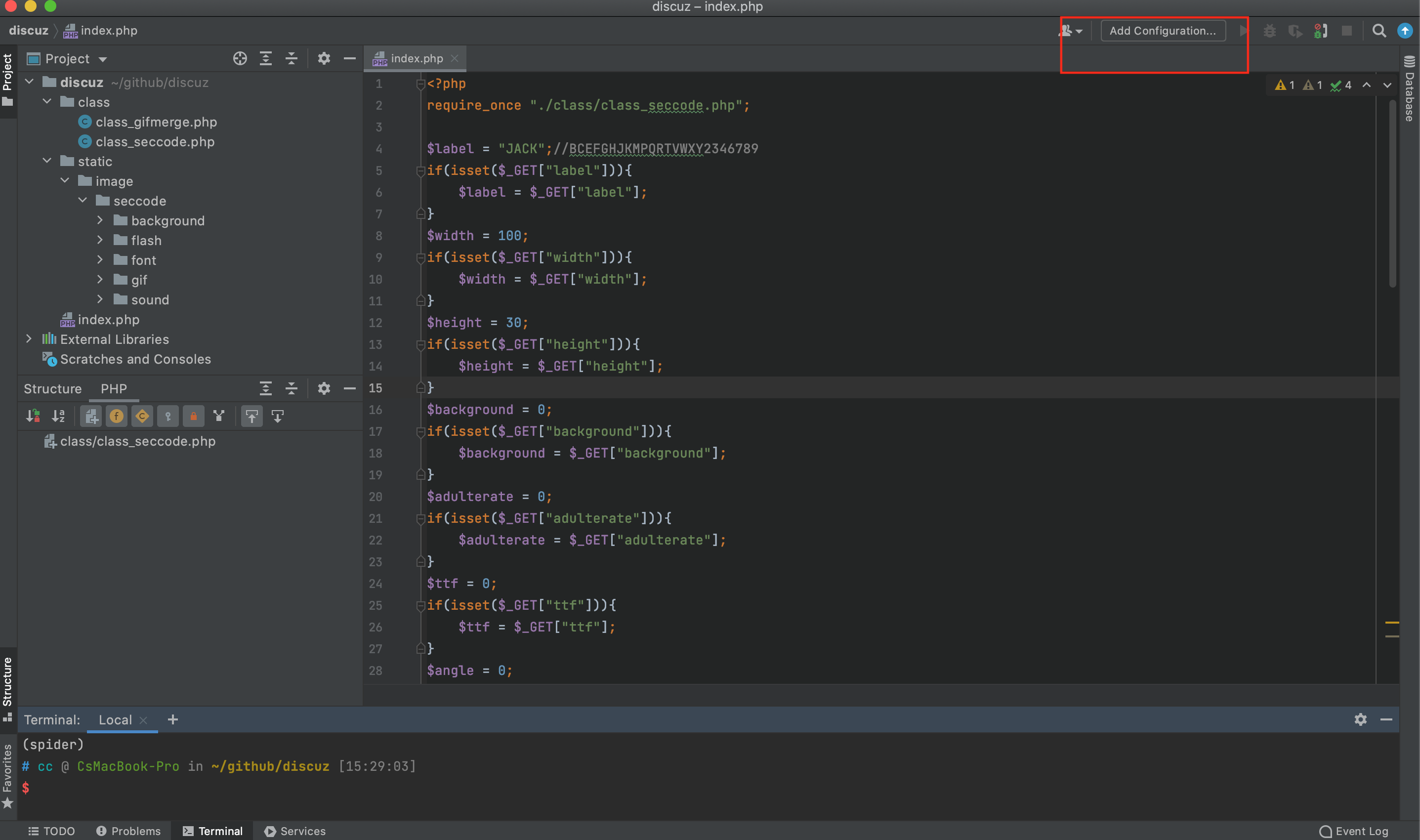
点击+添加一个PHP Built-in Web Server
修改Name,Host,Port,其中Name可以随便起,Host可以设为127.0.0.1或者0.0.0.0等,Port选择你电脑上没有被占用的端口即可,其他保持默认即可,然后保存设置
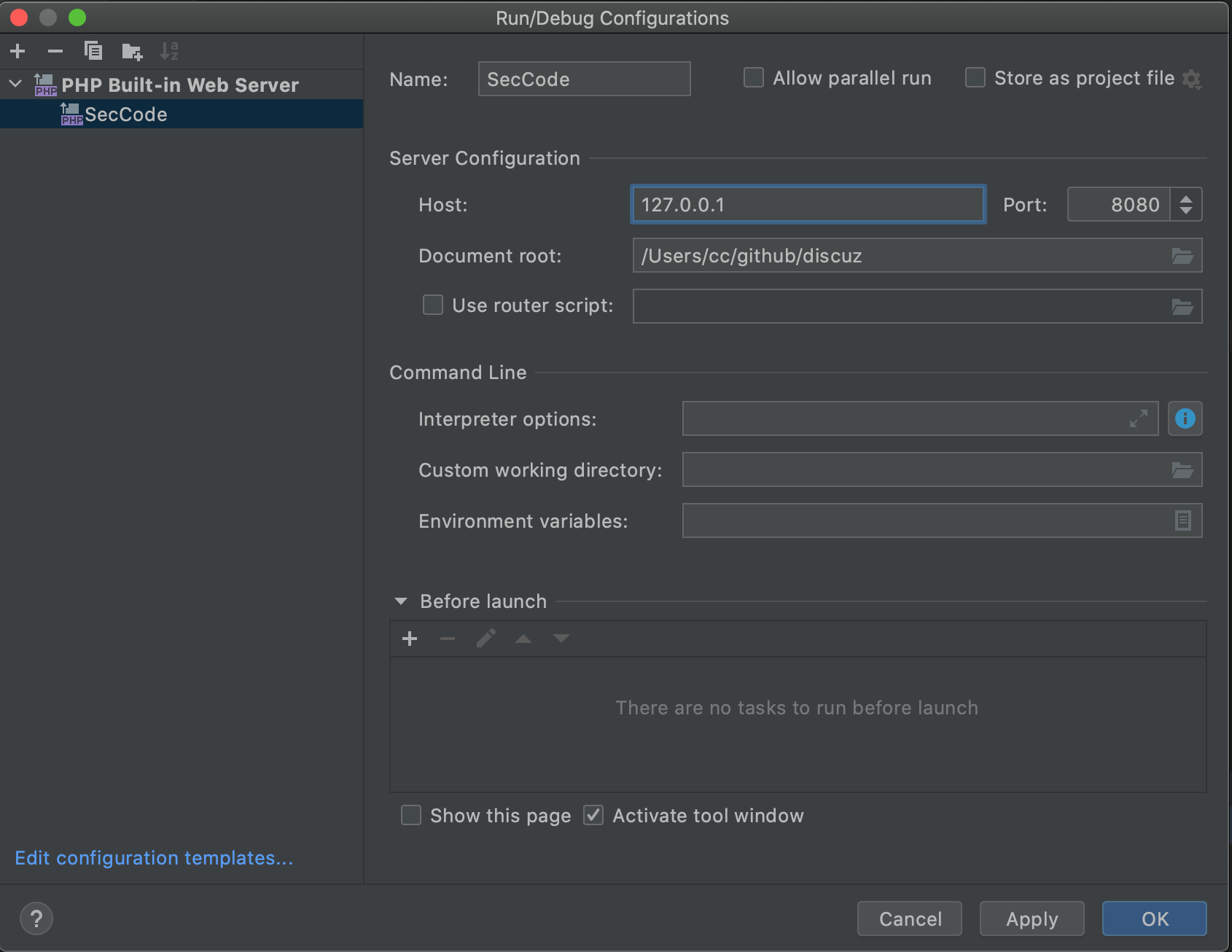
保存后,可以看到右上角有了绿色三角的运行按钮,点击运行,即可启动这个php项目
运行后,就可以用python批量生产验证码了,懂PHP的话其实应该可以修改代码直接PHP生成这些图即可,但奈何不会PHP,下面python代码同样也是改自这篇文章提供的Tensorflow实战(二):Discuz验证码识别,这里因为目标网站就是用的Discuz默认的"BCEFGHJKMPQRTVWXY2346789"词库,所以批量生成验证码时也只用这些来生成,减少干扰项,为了方便cnn_captcha识别,文件命名为"验证码_序号"的格式
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43#-*- coding:utf-8 -*-
from urllib.request import urlretrieve
import time, random, os
class Discuz():
def __init__(self):
# Discuz验证码生成图片地址
self.url = 'http://127.0.0.1:8080/index.php?label={}&width=160&height=60&background=1&adulterate=1&ttf=1&angle=1&scatter=1&color=1&size=1&shadow=1'
def random_captcha_text(self, captcha_size = 4):
"""
验证码一般都无视大小写;验证码长度4个字符
Parameters:
captcha_size:验证码长度
Returns:
captcha_text:验证码字符串
"""
# number = ['0','1','2','3','4','5','6','7','8','9']
# alphabet = ['a','b','c','d','e','f','g','h','i','j','k','l','m','n','o','p','q','r','s','t','u','v','w','x','y','z']
# char_set = number + alphabet
char_set="BCEFGHJKMPQRTVWXY2346789"
return ''.join(random.sample(char_set, 4))
def download_discuz(self, start=0, end=10000):
"""
下载验证码图片
Parameters:
nums:下载的验证码图片数量
"""
dirname = './Discuz'
if not os.path.exists(dirname):
os.mkdir(dirname)
for i in range(start, end):
label = self.random_captcha_text()
print('第%d张图片:%s下载' % (i + 1,label))
urlretrieve(url = self.url.format(label), filename = os.path.join(dirname, f'{label}_{i}.png'))
print('恭喜图片下载完成!')
if __name__ == '__main__':
dz = Discuz()
dz.download_discuz(0, 50000)至此已经生成了用于训练的图片数据集
训练模型
这里以用谷歌的colab为例来训练模型,没办法自己电脑上的显卡太弱,约等于无
首先上传打包后的验证码到谷歌云盘上,方便colab上访问
新建或者打开一个笔记本,选择左上角的修改 > 笔记本设置,可以选择使用GPU加速
挂载谷歌云盘(非必须,如果数据在谷歌云盘上,则可以挂载),打开网页后输入口令即可
1
2
3
4
5
6import os
from google.colab import drive
drive.mount('/content/drive')
# 查看是否挂载成功
os.listdir('.')
选择tensorflow_version 1.x运行环境
1
%tensorflow_version 1.x
从github上clone cnn_captcha
1
2! git clone https://github.com/nickliqian/cnn_captcha.git
! mkdir cnn_captcha/sample解压图片数据集
1
2
3
4! tar -zxvf '/content/drive/MyDrive/Discuz-50000.tar.gz' > /dev/null
! tar -zxvf '/content/drive/MyDrive/Discuz-50000-100000.tar.gz' > /dev/null
! tar -zxvf '/content/drive/MyDrive/Discuz-100000-200000.tar.gz' > /dev/null
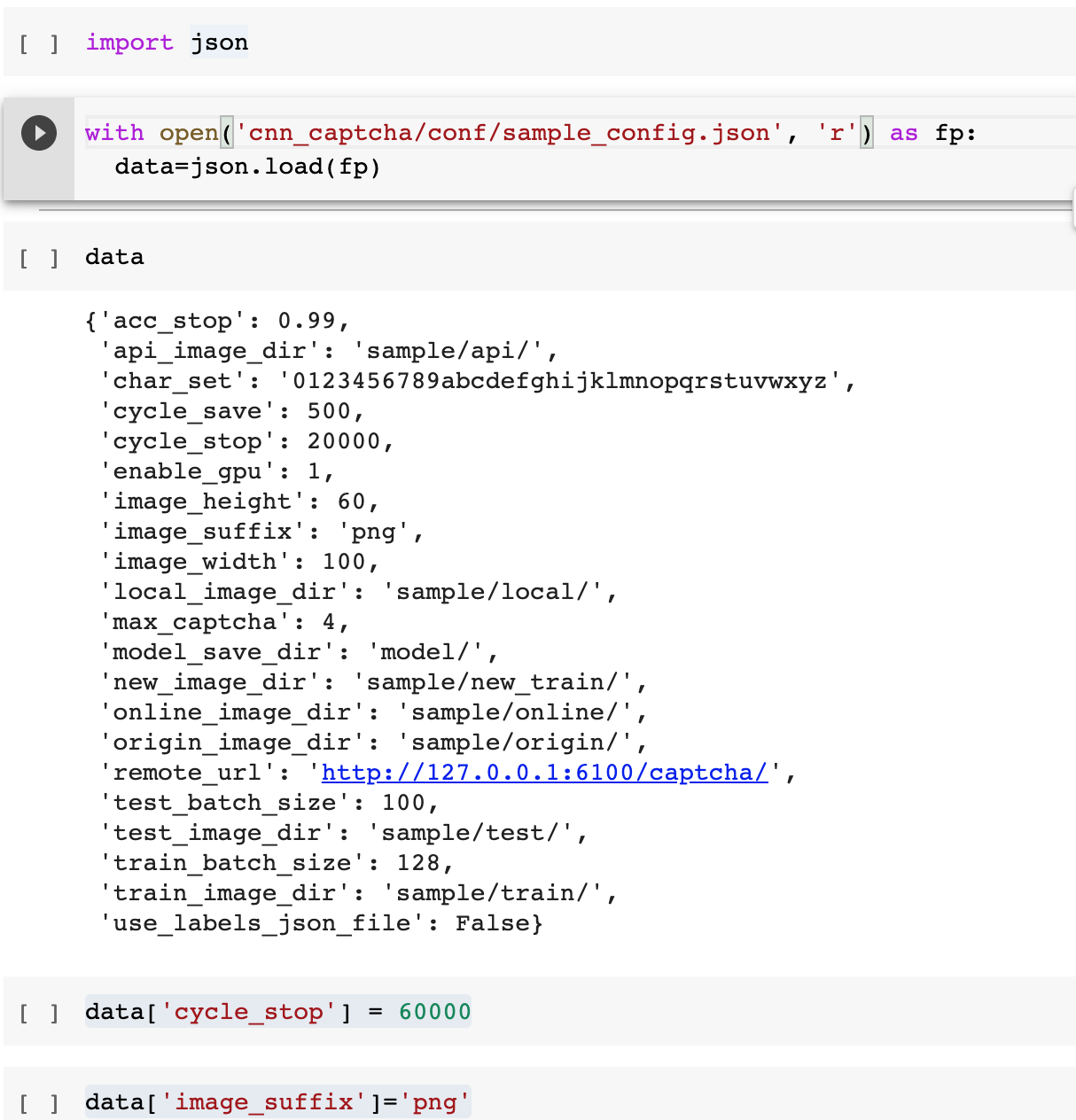
! mv Discuz cnn_captcha/sample/origin修改配置文件,如果不是在colab上运行,则可以直接文本编辑器修改json配置文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24! cd cnn_captcha/tools && python3 collect_labels.py
import json
with open('cnn_captcha/conf/sample_config.json', 'r') as fp:
data=json.load(fp)
# 修改需要的参数,其余参数可保持默认
# 最大训练次数
data['cycle_stop'] = 60000
# 数据集图片格式
data['image_suffix']='png'
# 图片宽高
data['image_width'] = 160
data['image_hight'] = 60
# 生成验证码的所有字符集合,Discuz默认只有这24个
data['char_set']='BCEFGHJKMPQRTVWXY2346789'
# 每次测试集使用的图片数量,内存小的机器可减小这个
data['test_batch_size']=100
# 每次训练集使用的图片数量,内存小的机器可减小这个
data['train_batch_size']=128
# 保存配置
with open('cnn_captcha/conf/sample_config.json', 'w') as fp:
json.dump(data, fp)
设置工作目录为cnn_captcha,方便后面运行训练主函数
1
os.chdir('cnn_captcha')
拆分图片为训练集和测试集
1
! python3 verify_and_split_data.py
拷贝train_model.py文件内容至colab笔记本输入框,然后运行main函数,这里不直接命令运行是因为,colab中使用命令运行,默认用的还是tensorflow 2,前面设置tensorflow 1就白设置了
训练完毕后打包model并保存到谷歌云盘
1
2
3
4
5
6os.chdir('/content/')
! tar -zcvf cnn_captcha.tar.gz cnn_captcha > /dev/null # 可以不打包整个cnn_captcha文件夹,看需求调整
! tar -zcvf model.tar.gz cnn_captcha/model > /dev/null # 这个即为训练好的模型
! cp model.tar.gz drive/MyDrive/ # 拷贝至谷歌云盘
! cp cnn_captcha.tar.gz drive/MyDrive/ # 拷贝至谷歌云盘完整colab的ipynb
实际用colab训练发现速度还是可以的:20万张图,按上面参数训练5万多次后,训练集字符和图片准确率100%,测试集的字符和图片准确率达到了99%,总耗时2小时。
启动识别API Server
本地git clone cnn_captcha
1
git clone https://github.com/nickliqian/cnn_captcha.git
下载训练好的模型,解压至cnn_captcha目录下
修改配置文件conf/sample_config.json里面的图片格式和大小为模型使用的大小,其他可以保持默认
创建API存放图片文件夹,这个文件夹可以在sample_config.json中修改,启动识别API server前需要有这个错误,否则识别时,报找不到文件错误
1
mkdir -p sample/api
启动server,这里运行环境也是需要tensorflow1.x,但是可以不需要GPU
1
python3 webserver_recognize_api.py
测试识别
使用jupyter notebook进行测试,方便展示验证码,比较识别结果
1
2
3
4
5
6
7
8import requests
# 这里参数说明('code.png', open('code.png', 'rb'), 'application'),前面的code.png随意,可以与后面的open中的名称不一致;open('code.png', 'rb')实际上是参数需要一个bytes型的数据,直接传一个bytes型的数据也是可以的;"application"保持默认即可
files = {'image_file': ('code.png', open('code.png', 'rb'), 'application')}
# http://127.0.0.1:6000/b为默认的API URL,可以在webserver_recognize_api.py中修改
r = requests.post(url='http://127.0.0.1:6000/b', files=files)
data = r.json()
data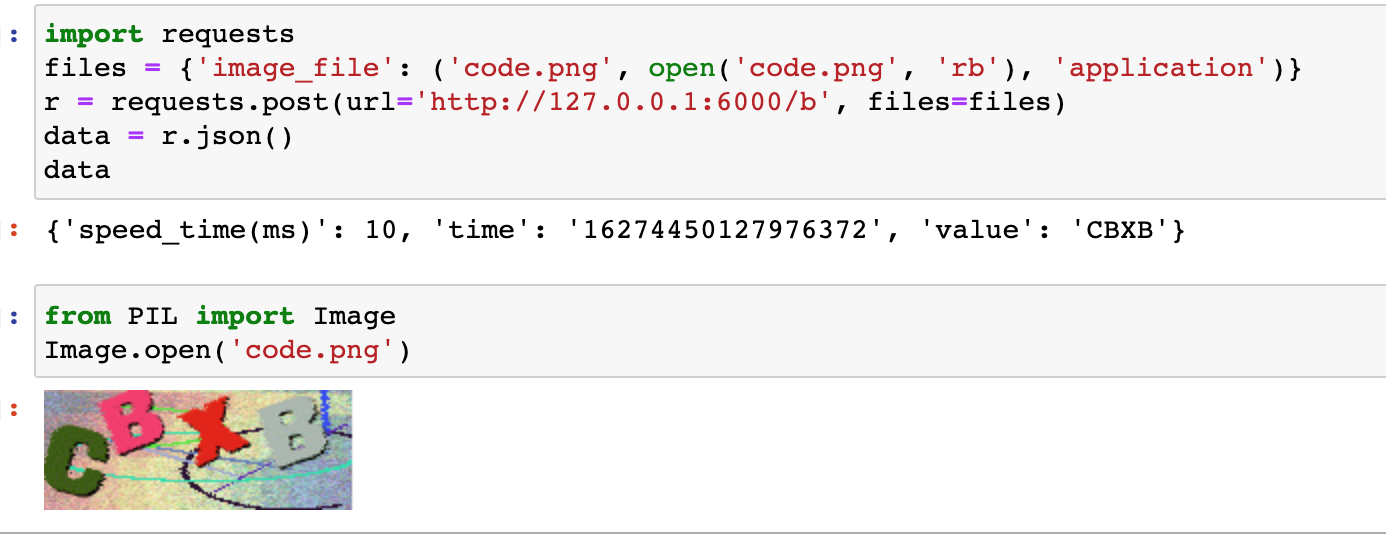
可以看到正确识别了CBXB,实际用某论坛的进行测试,图片准确率可达80%
至此可以用这个模型来进行一些使用了之类验证码的Discuz类论坛进行自动登录